 We’ve secured funding to power Signal-to-Revenue AI to GTM teams globally. →
We’ve secured funding to power Signal-to-Revenue AI to GTM teams globally. →Leads don’t slip away from a lack of traffic. They slip away in the moments right after intent shows ...
Red-Teaming Your GTM Agent: Failure Modes to Test Before Production
Published
Categorized as Uncategorized
Subscribe Now
A CMO described a rollout that went sideways in under five minutes. An agent replied to a prospect after a webinar with confidence, speed, and the wrong read on intent. The message was not offensive. It was simply wrong for that moment. The buyer disengaged, and the internal question followed fast: why did the agent act that way, and why did no one catch it sooner?
That question sits at the center of GTM risk. As teams adopt agentic workflows, mistakes can scale as fast as wins. This is why Wyzard, the Signal-to-Revenue AI, treats validation as a prerequisite, not an afterthought. With Agentic AI with HITL, safety gets built before production, not discovered inside it.
Red-teaming is how teams find failure before buyers do.
Why GTM Failures Rarely Start in Production
Many GTM failures look sudden from the outside. A bad reply. An off-brand message. A missed escalation. Inside the team, these failures usually start earlier. They begin with untested assumptions.
Agentic systems often behave well in demos and controlled scenarios. Real buyers introduce ambiguity, pressure, and messy edge cases. CMOs worry less about whether agents work and more about how they fail.
This is where Agentic AI and HITL matters. It lets teams test behavior under stress, with humans reviewing decisions before exposure.
The Risk of Unvalidated AI Agents
Unvalidated agents can look impressive at first. They respond quickly. They handle common questions. They follow scripts cleanly. Problems show up when conversations drift away from the happy path.
Common issues include:
- incorrect assumptions about buyer stage
- overconfident answers during sensitive moments
- missing escalation when intent turns serious
- looping replies that frustrate buyers
These are classic failure modes. They rarely show up in happy-path testing. They surface under pressure, when stakes rise.
Red-teaming exists to surface these risks early.
What Red-Teaming Means for GTM Agents
Red teaming is structured adversarial testing. Instead of asking whether an agent can succeed, teams ask how it can fail.
In GTM, red-teaming includes:
- simulating confusing, misleading, or hostile buyer inputs
- testing boundary conditions and edge cases
- probing escalation logic
- challenging brand and compliance guardrails
The goal is not to break the system publicly. The goal is to break it safely, before real buyers encounter it.
Within Agentic AI and HITL, red-teaming keeps humans watching how agents reason, not just what they output.
Failure Modes Every GTM Team Should Test
Most agentic GTM failures fall into predictable buckets. Red-teaming focuses on exposing them on purpose.
Common failure modes include:
- failing to escalate when buying intent increases
- escalating too early and flooding sales with noise
- tone mismatches during procurement or legal stages
- incorrect personalization assumptions
- incomplete context passed during handoff
Testing these scenarios before launch protects pipeline and brand.
Risk Testing Before Buyers Do
Risk testing puts agents into situations that mirror real-world pressure. That includes testing across channels, not just one interface.
Effective risk testing covers:
- website conversations
- event and field marketing follow-up
- LinkedIn outreach
- webinar engagement
- nurture email replies
Buyers move across channels fluidly. Agents must handle that fluidity without losing context or composure.
With Agentic AI and HITL, humans observe how agents respond under these conditions and adjust logic before rollout.
Why Context Matters in Red-Teaming
Testing without context misses the point. A pricing question means something very different from a student than from a buying committee member.
The GTM Intelligence Graph adds realism to red-teaming. It connects account attributes, engagement history, buying stage, and channel signals. Red-teaming scenarios become grounded in actual buyer journeys, not hypotheticals.
This context reveals subtle issues. An agent might respond appropriately in isolation and poorly once full account history is visible. The GTM Intelligence Graph makes those gaps clear.
Red-Teaming Inside a System of Outcomes
Red-teaming is about safety, and it is about results too.
Within a System of Outcomes, teams evaluate which failures actually impact revenue. Some mistakes are cosmetic. Others stall deals or erode trust.
By mapping red-team findings to outcomes, teams learn:
- which guardrails matter most
- where HITL intervention improves results
- how fixes change conversion and progression
This keeps red-teaming tied to business value, not fear-driven caution.
How WyzAgents Support Red-Teaming Before Go-Live
Wyzard, the Signal-to-Revenue AI, supports red-teaming directly through WyzAgents. Teams can run controlled simulations that never reach buyers.
These environments allow:
- testing agent behavior across scenarios
- observing decision logic with human oversight
- validating escalation and handoff rules
- refining messaging before launch
With Agentic AI and HITL, humans stay in the loop during testing, reviewing how agents think, not only the final message.
Red-Teaming Across the full GTM Surface
True validation requires breadth. Red-teaming should reflect how buyers actually engage.
Wyzard.ai supports testing across:
- website interactions
- event lead follow-up
- LinkedIn conversations
- webinar-driven engagement
- email-based nurture responses
This omni-channel view matters. An agent that performs well in one channel can fail in another if context gets lost or tone shifts.
The Role of AI GTM Engineers
Red-teaming does not run itself. AI GTM Engineers design test scenarios, define failure thresholds, and interpret results.
Their work includes:
- creating adversarial test cases
- aligning tests with brand and compliance rules
- refining decision logic based on findings
- preparing agents for real-world variability
This role helps Agentic AI and HITL to evolve safely as GTM strategies change.
Why CMOs Care About Red-Teaming
For CMOs, red-teaming protects more than pipeline. It protects trust.
One bad interaction can undo months of brand investment. Red-teaming shifts risk discovery earlier, before exposure. It lets CMOs scale engagement with confidence, knowing edge cases have been tested.
With Agentic AI and HITL, red-teaming becomes a standard part of GTM readiness, not a reaction to failure.
Production is the Wrong Place to Find Risk
Agentic scale magnifies everything. Wins grow faster. Mistakes travel further. Red-teaming finds weak points before they matter.
Agentic AI and HITL, supported by risk testing, informed by a GTM Intelligence Graph, and measured through a System of Outcomes, gives teams a way to move fast without betting trust on hope.
Wyzard, the Signal-to-Revenue AI, orchestrates every signal into revenue while making sure agents are ready for real buyers, not just demos.
If you want to see red-teaming inside real GTM workflows, book a demo and see Wyzard.ai in action.
Other blogs
The latest industry news, interviews, technologies, and resources.
February 23, 2026
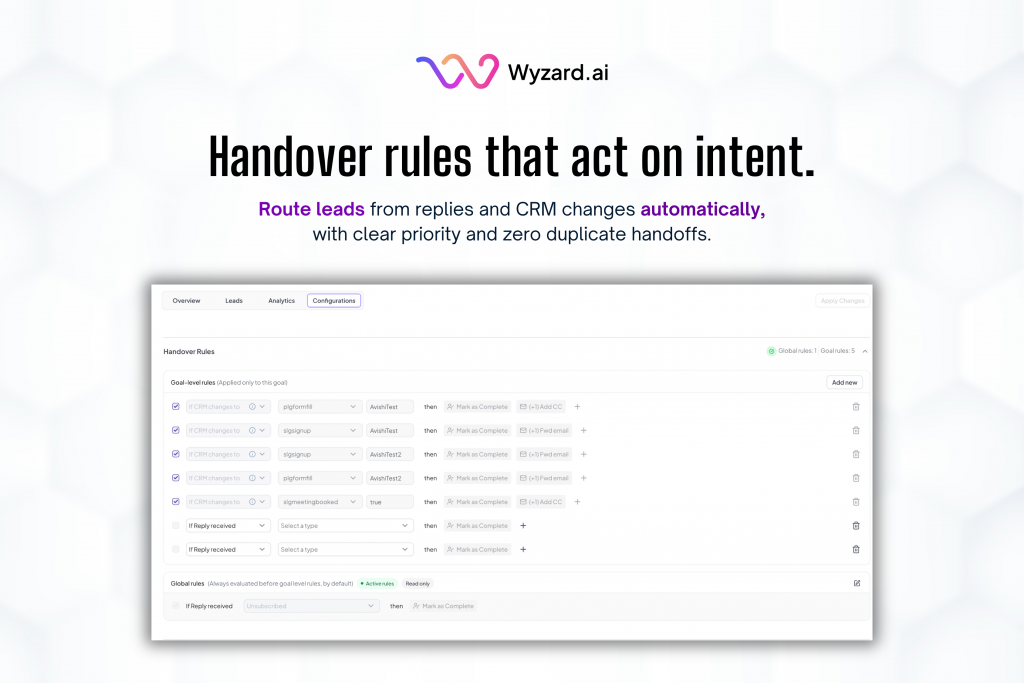
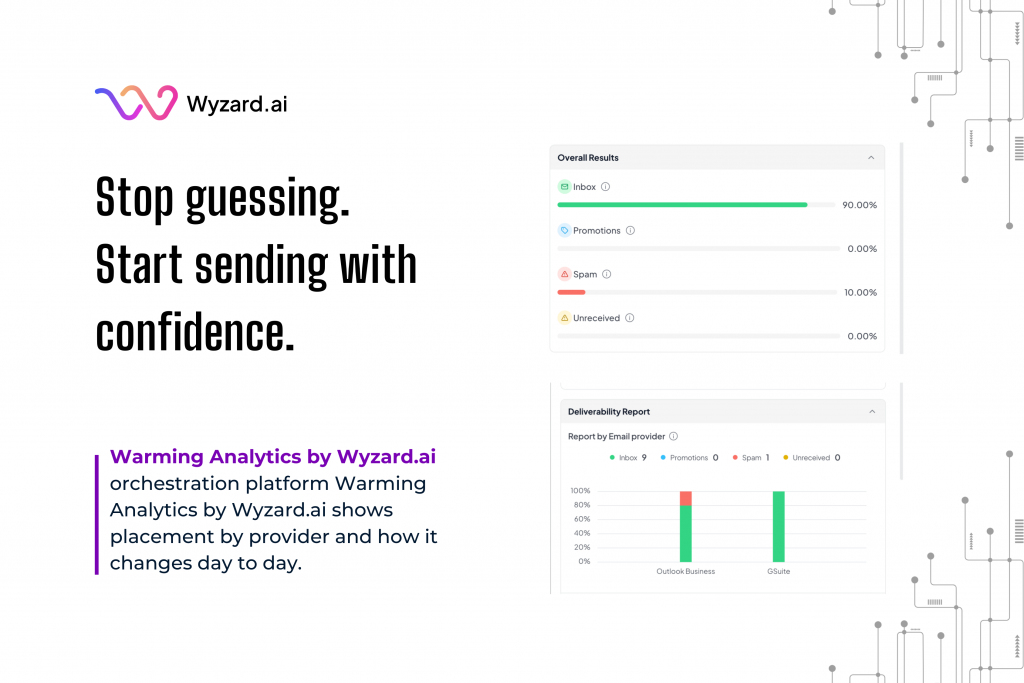
Warming Analytics: Know When a Mailbox Is Ready to Send
Outbound works best when trust stays intact. Many teams ramp up sending, then see replies drop or spam placement ...

February 20, 2026
How To Generate Leads at Events
You spent weeks planning the booth, flew your team across the country, and showed up ready to make an ...
